MSSQL에는 일반 인덱스 말고 INCLUDE INDEX(커버드/포괄 인덱스) 라는 인덱스를 만들 수 있다.
이번 시간에는 INCLUDE INDEX(커버드/포괄 인덱스)가 무엇인지 알아보고 일반 인덱스와의 비교 테스트를 진행해 보려고한다.
INCLUDE INDEX(커버드/포괄 인덱스)란?
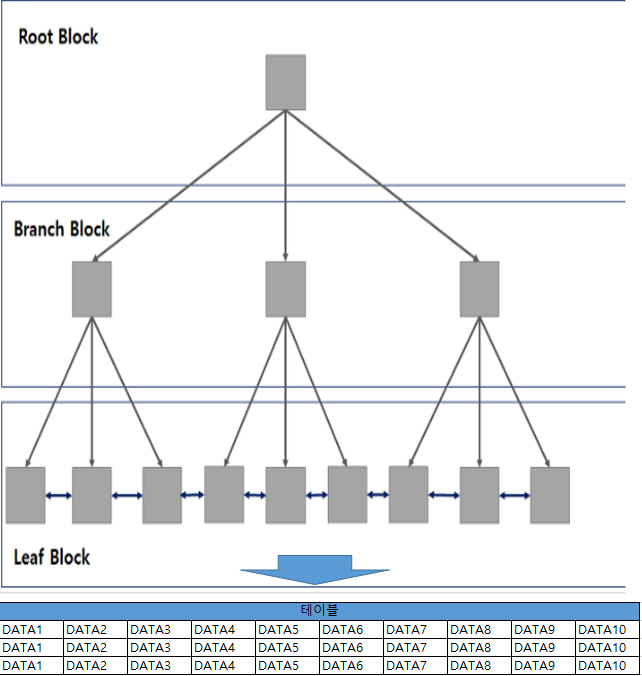
포괄 열이 있는 인덱스는 비클러스터형 인덱스의 리프 페이지에 데이터를 포함하고 있는 열을 의미한다.
비클러스터형 인덱스가 클러스터형 인덱스보다 느린 이유는 리프 페이지 이후에 다시 데이터 페이지를 찾아가야 하기 때문에 느려지는데
포괄 열이 있는 인덱스는 리프 페이지에 데이터까지 같이 존재하므로 데이터 페이지를 찾아가지 않아도 비클러스터형 인덱스에서 모든 작업이 종료된다.
이 것은 마치 클러스터형 인덱스를 검색하는 효과를 낼 수 있으므로 쿼리 성능을 높일 수 있다

INCLUDE INDEX(커버드/포괄 인덱스) 문법
CREATE NONCLUSTERED INDEX 인덱스명
ON 테이블명(컬럼명1)
INCLUDE (컬럼명2, 컬럼명3)
INCLUDE INDEX(커버드/포괄 인덱스) 특징
* 일반 인덱스의 최대 키 길이는 900바이트로 제한되지만 포괄 열이 있는 인덱스는 900바이트가 넘더라도 생성이 된다.
* 포괄 열이 있는 인덱스는 비클러스터형 인덱스에만 생성할 수 있다.
* 포괄 열이 있는 인덱스는 인덱스의 크기가 커지는 단점이 있다.
* 포괄 열이 있는 인덱스 생성 후에, 일부 SELECT문의 성능이 급격히 향상될 수 있다.
* 포괄 열이 있는 인덱스가 있더라도 SELECT의 열이 그 포괄 열에 포함되지 않으면 인덱스는 사용되지 않는다.
* 포괄 열이 있는 인덱스 생성 후에 INSERT/UPDATE/DELETE 문이 더 늦어질 수 있다.
(데이터 페이지와 인덱스의 리프 페이지에 두 번의 작업이 이루어져야 하므로 시간이 걸린다.)
INCLUDE INDEX(커버드/포괄 인덱스) 성능 성능비교
USE INDEX_TEST
GO
--테이블 생성
CREATE TABLE OrderT(
주문번호 int
,상품 varchar(100)
,주문일자 datetime
-- CONSTRAINT PK_OrderT_주문번호_상품 PRIMARY KEY CLUSTERED
-- (
-- 주문번호 ASC,
-- 상품 ASC
-- )
)
--데이터 입력
--9999개의 데이터를 입력
DECLARE @i INT
DECLARE @j INT
DECLARE @Lastnum INT
DECLARE @date datetime
SET @i = 1
SET @Lastnum = 10000
SET @date = '2023-03-01 00:00:00.000'
WHILE @i<@Lastnum
BEGIN
if @i <= 5000
insert into OrderT values (@i,'꿀'+convert(varchar(100), @i),@date+@i)
ELSE
insert into OrderT values (@i,'꿀9999',@date+@i)
SET @i = @i+1 --숫자 더하기
END;
GO
--데이터 확인
select * from OrderT
GO
--인덱스 생성
create nonclustered index IX_상품 on OrderT(상품)
create nonclustered index IX_상품_N주문일자 on OrderT(상품) INCLUDE (주문일자)
create nonclustered index IX_상품_주문일자 on OrderT(상품,주문일자)
성능비교1
select 상품 from OrderT with (index(IX_상품)) where 상품='꿀9999' and 주문일자>='2050-07-15 00:00:00.000' --1
select 상품 from OrderT with (index(IX_상품_N주문일자)) where 상품='꿀9999' and 주문일자>='2050-07-15 00:00:00.000' --2
select 상품 from OrderT with (index(IX_상품_주문일자)) where 상품='꿀9999' and 주문일자>='2050-07-15 00:00:00.000' --3

비용이 가장 많이드는 쿼리는 1번이며 가장 작게드는 쿼리는 3번이다.
1번 쿼리는 인덱스(IX_상품)를 사용하여 인덱스에서 상품명이='꿀9999'인 데이터를 가져온다.
하지만 주문일자를 인덱스에서 찾지 못하기 때문에 랜덤엑세스(ROWID를 통해서 테이블에서 데이터를 가져오는 현상)가 발생한다.
SQL서버에서는 이를 RID LOOKUP(row identifier=행식별자)이라고 한다.
2번 쿼리는 INCLUDE 인덱스(IX_상품_N주문일자)를 사용하여 랜덤엑세스(ROWID를 통해서 테이블에서 데이터를 가져오는 현상)를 제거하여 I/O 비용이 감소된다.
비용을 가장 많이 차지하는 랜덤엑세스를 제거하여 성능이 향상되었다
만약 인덱스를 '[상품 + 주문일자]' 순으로 생성하면'주문일자' 칼럼도 수직적 탐색에 사용될 수 있도록 그 값을 루프와 브랜치 블록에 저장한다.
하지만 '주문일자' 칼럼을 INCLUDE 옵션으로만 지정하면 그 값은 리프 블록에만 저장한다.(글 최상단 그림을 참조)
따라서 수직적 탐색에는 사용되지 못하고 수평적 탐색을 위한 필터 조건(보통 select 절)으로만 사용되어 스캔하는 범위는 자체를 줄이지는 못했다.
[Included Column 특징 더 알아보기.]
Included Column을 사용하게 되면 인덱스의 키는 B-Tree 구조의 모든 노드에 저장이 되는 반면, Included Column은 Leaf 노드 수준에서만 저장되기 때문에 많은 칼럼을 포함시키더라도
더욱 효율적으로 생성할 수 있게 되면서 동시에 쿼리에서 찾고자 하는 데이터를 데이터 페이지나 클러스터형 인덱스에 접근하지 않고 인덱스 수준에서 처리할 수 있게 되기 때문에 I/O를 줄일 수 있습니다.
* 이렇게 데이터를 조회할 때 데이터 페이지까지 내려가지 않고 인덱스 수준에서 조회를 완료할 수 있는 쿼리를 Covering Query라고 부르며, 사용된 인덱스를 Covered Index라고 부릅니다.
3번 쿼리는 인덱스를 '[상품 + 주문일자]'로 만들어서 수직적 탐색이 가능하여 2번쿼리에서 제거하지 못한 스캔 범위까지 줄이는 것이 가능하다.
따라서 비용이 가장 적게 든다.
성능비교2
이번에는 위에서 말한 '수직적 탐색'이 불가능하는 내용에 대해 알아보자.
1번쿼리는 '주문일자'가 INCLUDE 인덱스이고
2번쿼리는 '주문일자'가 일반 인덱스 이다.
1번 쿼리의 실행 계획을 보면 INCLUDE 인덱스(IX_상품_N주문일자)는 정렬이 되어있지 않기 때문에(수직적 탐색에 사용불가)
Sort 계획이 추가로 들어가여 비용이 증가하는 것 을 볼수있다.
order by절
select 상품 from OrderT with (index(IX_상품_N주문일자)) where 상품='꿀9999' order by 주문일자 desc --1번
select 상품 from OrderT with (index(IX_상품_주문일자)) where 상품='꿀9999' order by 주문일자 desc --2번
select절 distinct
중복제거(distinct)를 위해 정렬이 필요하다
select distinct(주문일자) from OrderT with (index(IX_상품_N주문일자)) where 상품='꿀9999' --1번
select distinct(주문일자) from OrderT with (index(IX_상품_주문일자)) where 상품='꿀9999' --2번
GROUP BY
단독으로 사용되면 중복값을 제거하는 distinct와 동일하게 동작한다.
select count(상품) as 상품수량,주문일자 from OrderT with (index(IX_상품_N주문일자)) where 상품='꿀9999' group by 주문일자--1번
select count(상품) as 상품수량,주문일자 from OrderT with (index(IX_상품_주문일자)) where 상품='꿀9999' group by 주문일자--2번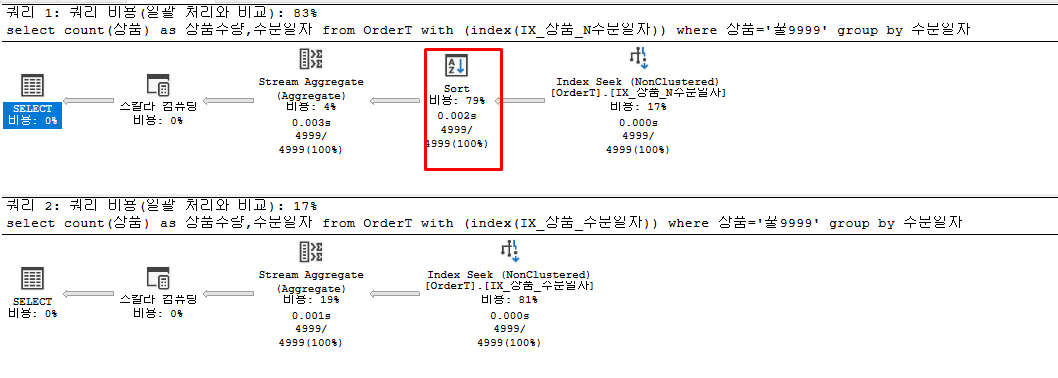
max
최대값을 구하기 위해서는 정렬이 필요하다
select MAX(상품) as 상품수량,주문일자 from OrderT with (index(IX_상품_N주문일자)) where 상품='꿀9999' group by 주문일자--1
select MAX(상품) as 상품수량,주문일자 from OrderT with (index(IX_상품_주문일자)) where 상품='꿀9999' group by 주문일자--2
min
최소값을 구하기 위해서는 정렬이 필요하다
select MIN(상품) as 상품수량,주문일자 from OrderT with (index(IX_상품_N주문일자)) where 상품='꿀9999' group by 주문일자--1
select MIN(상품) as 상품수량,주문일자 from OrderT with (index(IX_상품_주문일자)) where 상품='꿀9999' group by 주문일자--2
이러한 특성을 잘 확인하여 인덱스 생성시 참고하면 좋을 것 같다.
'IT > MSSQL' 카테고리의 다른 글
| [MSSQL]Index spool(Eager, Lazy)개념 및 차이점 (0) | 2023.04.15 |
|---|---|
| [MSSQL]관계읽기(데이터 모델링 필수관계 선택관계) (0) | 2023.04.15 |
| [MSSQL] UPDATE SELECT 구문 쿼리 튜닝(성능 및 속도 개선) (0) | 2023.04.15 |
| [MSSQL] in,not in, exists, not exists 내부 동작로직 및 예제 (0) | 2023.04.15 |
| [MSSQL]복합(결합) 인덱스 생성규칙 - 순서에 따른 I/O 비용차이(랜덤액세스) (0) | 2023.04.15 |




댓글