728x90
실행 계획을 보다 보면 index spool(Eager Spool, Lazy Spool) 같은 스풀 연산자 계획을 볼 수 있다.
Spool 이란 무엇이며 어떤 상황에서 발생하는지 알아보고 spool을 제거하는 방법에 대해서 추가로 알아보자.
Spool이란?
- 스풀 작업은 단순히 데이터의 임시 저장소입니다 .
- 데이터는 원본 테이블에서 읽고 Tempdb 데이터베이스의 작업 테이블에 저장됩니다
- 옵티마이저가 테이블 또는 인덱스에 대한 다중 액세스를 수행하는 것보다 작업 테이블에서 데이터를 읽는 것이 더 효율적이라고 평가할 때 사용됩니다
| Eager Spool | Eager Spool 및 Lazy Spool은 항상 다른 물리적 스풀 연산자와 함께 표시됩니다. Eager Spool은 이전 오퍼레이터의 요청을 받으면 한 번에 모든 행을 가져와서 TEMPDB로 전송합니다. |
| Lazy Spool | Lazy Spool은 이전 운영자의 요청을 받으면 해당 행만 가져와서 tempdb로 전송합니다. Nested Loop 연산자로 볼 수 있습니다. 중첩된 루프에서 행별 읽기가 수행되기 때문에 |
Spool제거방법
적절한 인덱스를 생성하면 spool을 제거 할 수 있습니다.
[개선전]
생성된 인덱스 : CREATE CLUSTERED INDEX CIDX_T_OUTER_data ON T_OUTER (date)
SELECT f.id , f.txt, (SELECT s.value
FROM T_INNER s
WHERE f.id = s.id) value
FROM T_OUTER f
WHERE date BETWEEN '2020-01-01' AND '2020-01-02'
GO
스칼라 서브쿼리 내부 테이블(T_INNER)의 id 컬럼에 인덱스가 없어서 index spool(Lazy Spool)을 동반한 전체 테이블 스캔이 반복되면서 I/O 비용이 높게 발생한다.
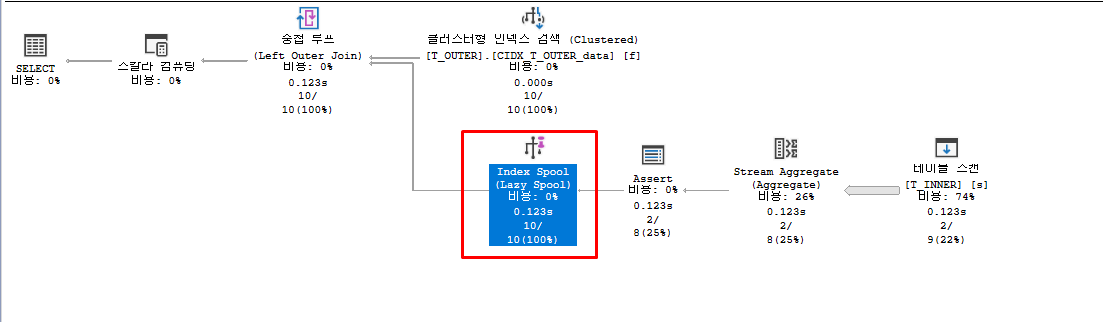
[개선후]
index spool(Lazy Spool)은 데이터를 반복해서 읽어야 할 경우 인덱스가 없으면 발생할 수 있다.
필요한 데이터만 인덱스 탐색을 할 수 있도록 후행 테이블( T_INNER )에 조인 조건 컬럼기준 인덱스를 생성해 준다.
추가 생성된 인덱스 : CREATE INDEX NIDX_T_INNER_id_Nvalue ON T_INNER (id) INCLUDE (value)
SELECT f.id , f.txt, (SELECT s.value
FROM T_INNER s
WHERE f.id = s.id) value
FROM T_OUTER f
WHERE date BETWEEN '2020-01-01' AND '2020-01-02'
GO

반응형
'IT > MSSQL' 카테고리의 다른 글
| [MSSQL] MAXRECURSION 힌트(무한 루프 진입방지 제한) (0) | 2023.04.15 |
|---|---|
| [MSSQL] CROSS APPLY를 통한 성능개선(부분 범위처리 TOP 5) (0) | 2023.04.15 |
| [MSSQL]관계읽기(데이터 모델링 필수관계 선택관계) (0) | 2023.04.15 |
| [MSSQL]INCLUDE INDEX(커버드/포괄 인덱스) 성능차이 설명 및 예제 (0) | 2023.04.15 |
| [MSSQL] UPDATE SELECT 구문 쿼리 튜닝(성능 및 속도 개선) (0) | 2023.04.15 |




댓글